
Video Understanding: From Tags to Language
1 059
58.8
Microsoft Research335 тыс
Следующее
 08.11.17 – 77826:34
08.11.17 – 77826:34Популярные
 331 день – 6635:18
331 день – 6635:18 06.12.23 – 1 72032:52
06.12.23 – 1 72032:52Опубликовано 8 ноября 2017, 18:12
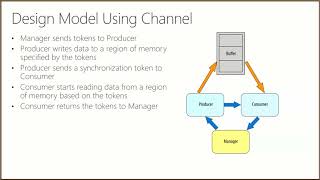
The increasing ubiquity of devices capable of capturing videos has led to an explosion in the amount of recorded video content. Instead of “eyeballing” the videos for potentially useful information, it has therefore been a pressing need to develop automatic video analysis and understanding algorithms for various applications. However, understanding videos on a large scale remains challenging: large variations and complexities, time-consuming annotations, and a wide range of involved video concepts. In light of these challenges, my research towards video understanding focuses on designing effective network architectures to learn robust video representations, learning video concepts from weak supervision and building a stronger connection between language and vision. In this talk, I will first introduce a Deep Event Network (DevNet) that can simultaneously detect pre-defined events and localize spatial-temporal key evidence. Then I will show how web crawled videos and images could be utilized for learning video concepts. Finally, I will present our recent efforts to connect visual understanding to language through attractive visual captioning and visual question segmentation.
See more on this video at microsoft.com/en-us/research/v...
See more on this video at microsoft.com/en-us/research/v...
Свежие видео

 10 дней – 5014:00
10 дней – 5014:00
 11 дней – 2612:19
11 дней – 2612:19
 13 дней – 786 9243:13:31
13 дней – 786 9243:13:31
 13 дней – 1 5740:50
13 дней – 1 5740:50
 14 дней – 22 97110:41
14 дней – 22 97110:41 14 дней – 8 2841:00
14 дней – 8 2841:00Случайные видео

 7 дней – 32 14817:42
7 дней – 32 14817:42
 114 дней – 24 6890:46
114 дней – 24 6890:46
 242 дня – 2 000 1061:00
242 дня – 2 000 1061:00
 280 дней – 2 3820:54
280 дней – 2 3820:54
 03.11.22 – 3452:22
03.11.22 – 3452:22 17.04.16 – 1 420 96831:29
17.04.16 – 1 420 96831:29
 6 часов – 73310:12
6 часов – 73310:12
 7 дней – 169 2299:58
7 дней – 169 2299:58
 8 дней – 82 09411:08
8 дней – 82 09411:08 8 дней – 10 5810:16
8 дней – 10 5810:16 9 дней – 2543:58
9 дней – 2543:58 10 дней – 28 19612:18
10 дней – 28 19612:18
 11 дней – 12 2090:31
11 дней – 12 2090:31 6 дней – 489 8282:58:34
6 дней – 489 8282:58:34
 7 дней – 67210:59
7 дней – 67210:59