
Stochastic Approximation and Reinforcement Learning: Hidden Theory and New Super-Fast Algorithms
6 395
25.4
Microsoft Research334 тыс
Следующее
 20.11.18 – 1 3891:14:25
20.11.18 – 1 3891:14:25Популярные
 354 дня – 17022:21
354 дня – 17022:21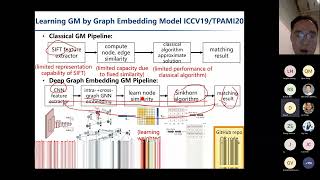 12.12.22 – 2 51836:34
12.12.22 – 2 51836:34Опубликовано 20 ноября 2018, 16:07
Stochastic approximation algorithms are used to approximate solutions to fixed point equations that involve expectations of functions with respect to possibly unknown distributions. Among many algorithms in machine learning, reinforcement learning algorithms such as TD- and Q-learning are two of its most famous applications.
This talk will provide an overview of stochastic approximation, with focus on optimizing the rate of convergence. Based on this general theory, the well known slow convergence of Q-learning is explained: the variance of the algorithm is typically infinite. Three new Q-learning algorithms are introduced to dramatically improve performance: (i) The Zap Q-learning algorithm that has provably optimal asymptotic variance, and resembles the Newton-Raphson method in a deterministic setting (ii) The PolSA algorithm that is based on Polyak'smomentum technique, but with a specialized matrix momentum, and (iii) The NeSA algorithm based on Nesterov's acceleration technique.
Analysis of (ii) and (iii) require entirely new analytic techniques. One approach is via coupling: conditions are established under which the parameter estimates obtained using the PolSA algorithm couple with those obtained using the Newton-Raphson based algorithm. Numerical examples confirm this behavior, and the remarkable performance of these algorithms.
See more at microsoft.com/en-us/research/v...
This talk will provide an overview of stochastic approximation, with focus on optimizing the rate of convergence. Based on this general theory, the well known slow convergence of Q-learning is explained: the variance of the algorithm is typically infinite. Three new Q-learning algorithms are introduced to dramatically improve performance: (i) The Zap Q-learning algorithm that has provably optimal asymptotic variance, and resembles the Newton-Raphson method in a deterministic setting (ii) The PolSA algorithm that is based on Polyak'smomentum technique, but with a specialized matrix momentum, and (iii) The NeSA algorithm based on Nesterov's acceleration technique.
Analysis of (ii) and (iii) require entirely new analytic techniques. One approach is via coupling: conditions are established under which the parameter estimates obtained using the PolSA algorithm couple with those obtained using the Newton-Raphson based algorithm. Numerical examples confirm this behavior, and the remarkable performance of these algorithms.
See more at microsoft.com/en-us/research/v...
Свежие видео



 3 дня – 41 29713:36
3 дня – 41 29713:36
 4 дня – 976 5401:00
4 дня – 976 5401:00
 4 дня – 1 3540:41
4 дня – 1 3540:41
 5 дней – 1 3540:19
5 дней – 1 3540:19 12 дней – 2 5870:42
12 дней – 2 5870:42Случайные видео

 127 дней – 49 7713:04
127 дней – 49 7713:04
 169 дней – 422 76510:53
169 дней – 422 76510:53
 03.02.23 – 39 78443:29
03.02.23 – 39 78443:29 27.05.22 – 15 40442:17
27.05.22 – 15 40442:17
 12.01.22 – 540 2889:45
12.01.22 – 540 2889:45
 08.11.06 – 114 7741:01
08.11.06 – 114 7741:01
 1 день – 5110:40
1 день – 5110:40
 1 день – 102 2893:33
1 день – 102 2893:33
 2 дня – 2 5661:30
2 дня – 2 5661:30
 2 дня – 019:31
2 дня – 019:31
 4 дня – 345 8880:57
4 дня – 345 8880:57 4 дня – 327 7099:00
4 дня – 327 7099:00
 9 дней – 3 12938:03
9 дней – 3 12938:03
 2 дня – 12 40216:32
2 дня – 12 40216:32
 3 дня – 1 0284:01
3 дня – 1 0284:01