
Grounded Visual Generation
605
16.8
Microsoft Research357 тыс
Следующее
 15.09.21 – 1 2361:23:19
15.09.21 – 1 2361:23:19Популярные


Опубликовано 15 сентября 2021, 18:44
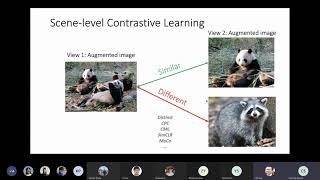
Multi-modal data provides an exciting opportunity to train grounded generative models that synthesize images consistent with real world phenomena. In this talk, I will share several of our recent efforts towards creating grounded visual generation models: (1) introducing user attention grounding for text-to-image synthesis, (2) improving text-to-image generation results with stronger language grounding, and (3) taking steps towards creating spatially grounded world models for embodied vision-and-language tasks.
Speaker: Jing Yu Koh, Google
MSR Deep Learning team: microsoft.com/en-us/research/g...
Speaker: Jing Yu Koh, Google
MSR Deep Learning team: microsoft.com/en-us/research/g...
Свежие видео

 22 часа – 30 3357:29
22 часа – 30 3357:29



 5 дней – 2 305 3710:26
5 дней – 2 305 3710:26
 8 дней – 1 21130:18
8 дней – 1 21130:18
 99 дней – 3 2750:16
99 дней – 3 2750:16Случайные видео

 242 дня – 454 93920:05
242 дня – 454 93920:05
 249 дней – 13 4930:22
249 дней – 13 4930:22
 04.11.23 – 8643:35
04.11.23 – 8643:35
 20.08.23 – 23 0200:26
20.08.23 – 23 0200:26
 01.12.12 – 32 0364:50
01.12.12 – 32 0364:50



 3 дня – 1 9570:12
3 дня – 1 9570:12
 4 дня – 1 9791:12
4 дня – 1 9791:12
 7 дней – 131 2378:27
7 дней – 131 2378:27
 7 дней – 3961:07
7 дней – 3961:07
 10 дней – 30 0396:35
10 дней – 30 0396:35 14 дней – 13 6510:42
14 дней – 13 6510:42