
Panel: Generalization in reinforcement learning
575
24
Microsoft Research334 тыс
Следующее
Популярные

 270 дней – 1 5371:07:34
270 дней – 1 5371:07:34Опубликовано 25 января 2022, 1:29
Speakers:
Mingfei Sun, Researcher, Microsoft Research Cambridge
Roberta Raileanu, PhD Student, NYU
Wendelin Böhmer, Assistant Professor, Delft University of Technology
Harm van Seijen, Principal Research Manager, Microsoft Research Montreal
Cheng Zhang, Principal Researcher, Microsoft Research Cambridge
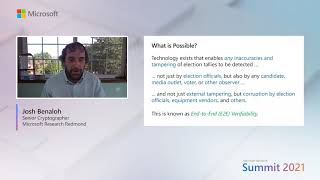
The ability for a reinforcement learning (RL) policy to generalize is a key requirement for the broad application of RL algorithms. This generalization ability is also essential to the future of RL—both in theory and in practice. Join Microsoft researchers Harm van Seijen, Cheng Zhang, and Mingfei Sun, along with Dr. Wendelin Boehmer from Delft University of Technology and Dr. Roberta Raileanu from New York University, as they examine how agents struggle to transfer learned policies to new environments or tasks and explore why generalization remains challenging for state-of-the-art deep RL algorithms. In addition, they will discuss open questions about the right way to think about generalization in RL, the right way to formalize the problem, and the most important tasks to be considered for generalization. Together, you will explore the importance of studying generalization in RL, the recent research progress in generalization in RL, the open challenges, and the potential research directions in this area.
Learn more about the 2021 Microsoft Research Summit: Aka.ms/researchsummit
Mingfei Sun, Researcher, Microsoft Research Cambridge
Roberta Raileanu, PhD Student, NYU
Wendelin Böhmer, Assistant Professor, Delft University of Technology
Harm van Seijen, Principal Research Manager, Microsoft Research Montreal
Cheng Zhang, Principal Researcher, Microsoft Research Cambridge
The ability for a reinforcement learning (RL) policy to generalize is a key requirement for the broad application of RL algorithms. This generalization ability is also essential to the future of RL—both in theory and in practice. Join Microsoft researchers Harm van Seijen, Cheng Zhang, and Mingfei Sun, along with Dr. Wendelin Boehmer from Delft University of Technology and Dr. Roberta Raileanu from New York University, as they examine how agents struggle to transfer learned policies to new environments or tasks and explore why generalization remains challenging for state-of-the-art deep RL algorithms. In addition, they will discuss open questions about the right way to think about generalization in RL, the right way to formalize the problem, and the most important tasks to be considered for generalization. Together, you will explore the importance of studying generalization in RL, the recent research progress in generalization in RL, the open challenges, and the potential research directions in this area.
Learn more about the 2021 Microsoft Research Summit: Aka.ms/researchsummit
Свежие видео

 5 дней – 8531:53
5 дней – 8531:53
 6 дней – 1 028 71816:58
6 дней – 1 028 71816:58
 9 дней – 1550:53
9 дней – 1550:53
 10 дней – 206 4450:16
10 дней – 206 4450:16
 10 дней – 1396:28
10 дней – 1396:28

Случайные видео

 55 дней – 1 8490:46
55 дней – 1 8490:46
 104 дня – 1 1890:27
104 дня – 1 1890:27
 128 дней – 38 7271:45
128 дней – 38 7271:45
 04.12.22 – 79 4366:36
04.12.22 – 79 4366:36 10.07.21 – 619 5341:32:58
10.07.21 – 619 5341:32:58 03.10.09 – 4 70948:42
03.10.09 – 4 70948:42

 5 дней – 97 85633:17
5 дней – 97 85633:17
 6 дней – 141 56126:46
6 дней – 141 56126:46 9 дней – 192 6740:41
9 дней – 192 6740:41 12 дней – 1 506 42820:29
12 дней – 1 506 42820:29
 14 дней – 6476:27
14 дней – 6476:27
 15 дней – 29 01616:17
15 дней – 29 01616:17
 1 день – 166 1987:38
1 день – 166 1987:38
